Web Insights Engine Overview
The Web Insights Engine extracts structured information, insights, and content from websites by crawling URLs. It supports vision mode for visual analysis, custom extraction instructions, and schema-based output formatting. Can handle Reddit URLs and Amazon product pages through specialized extraction.Engine Inputs
The Web Insights Engine Configuration has the following parameters:Core Parameters
- url: required. The website URL you want to extract information from.
- instruction: required (in AI extraction mode). Instructions for AI to analyze and extract data from the webpage.
- output_schema: required (in AI extraction mode). JSON schema defining the structure of data to extract. Follows the standard JSON schema specification.
- model: optional. The AI model to use (default:
gpt-5.1-2025-11-13). - vision_mode: optional. Enable visual analysis of the webpage screenshot in addition to text content (default: False).
Crawl Configuration
The crawl_config object provides advanced settings for how the website should be crawled:- crawling_only: optional. Skip AI extraction and return raw scraped content (default: False). When enabled,
instructionandoutput_schemaare not required. - min_wait_time_sec: optional. Time to wait for page to load in seconds (default: 0, range: 0-60).
- save_html: optional. Save the original HTML source code (default: False).
- save_markdown: optional. Save a clean, formatted markdown version of the webpage content (default: False).
- save_screenshot: optional. Capture a visual screenshot of the webpage (default: False).
- collect_web_analytics: optional. Capture network request/response data in HAR format (default: False).
Engine Output
The output will be a JSON value matching the structure specified in the output_schema. Whencrawling_only is enabled, returns the raw scraped content instead.
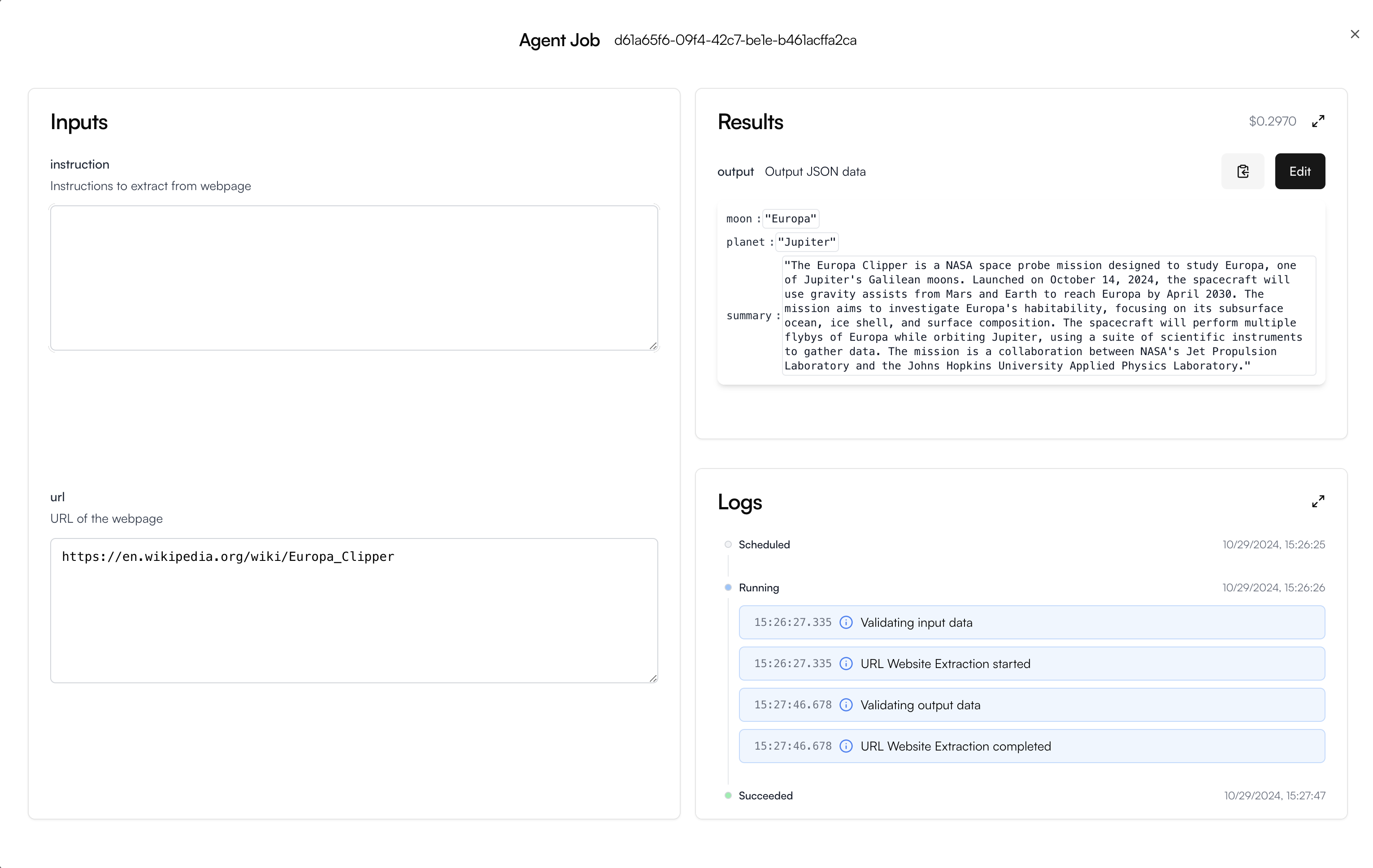
Web Insights Example
Let’s run through an example using this engine together.
Configure the engine as follows
$ starts a template string
- url: $
- instruction: $
- model: gpt-5.1-2025-11-13
- vision_mode: False
- output_schema: Copy and paste the JSON schema below (hit Use Text).

Fill in the Agent inputs
Leave instruction empty.url: https://en.wikipedia.org/wiki/Europa_ClipperHere are the filled-in Agent inputs: