Document Insights Engine Overview
The Document Insights Engine extracts structured information, insights, and data from PDF documents using AI. It processes documents in batches, supports schema-based extraction, source tracing, and handles multi-page documents efficiently.Engine Inputs
The Document Insights Engine Configuration has the following parameters:- instructions: required. Instructions for the AI describing what to extract from the PDF. Can also use alias
instruction. - pdf_files: required. PDF files to extract insights from. Can be file uploads, URLs, or file IDs. Supports multiple files (comma/newline separated). Can also use alias
pdf_file. - batch_size: optional. Number of PDF pages to process in each batch (default: 10, range: 1-50). Larger batches are faster but may affect quality.
- model: optional. The AI model to use (default:
gpt-4.1-2025-04-14). - temperature: optional. Controls randomness in output (default: 0.0). Range: 0.0 (deterministic) to 1.0 (most random).
- use_source: optional. Trace the sources of extracted data (default: False). Adds cost when enabled.
- convert_to_images: optional. Convert PDF pages to images and send to the model along with text (default: True). Improves extraction for visual documents.
- output_schema: optional. JSON schema defining the structure of data to extract. Follows the standard JSON schema specification.
Engine Output
The output will be a JSON value matching the structure specified in the output_schema (if defined). Without a schema, returns extracted content in a default format.Example Usage
Create an Agent
Click on the “Add Agent” button in the top right corner of the Agents page.
Configure the engine
$ starts a template string
- instructions: $instructions
- pdf_files: $pdf_files
- batch_size: 10
- model: gpt-4.1-2025-04-14
- temperature: 0.0
- convert_to_images: True
- output_schema: Copy and paste the JSON schema below:

Run a job
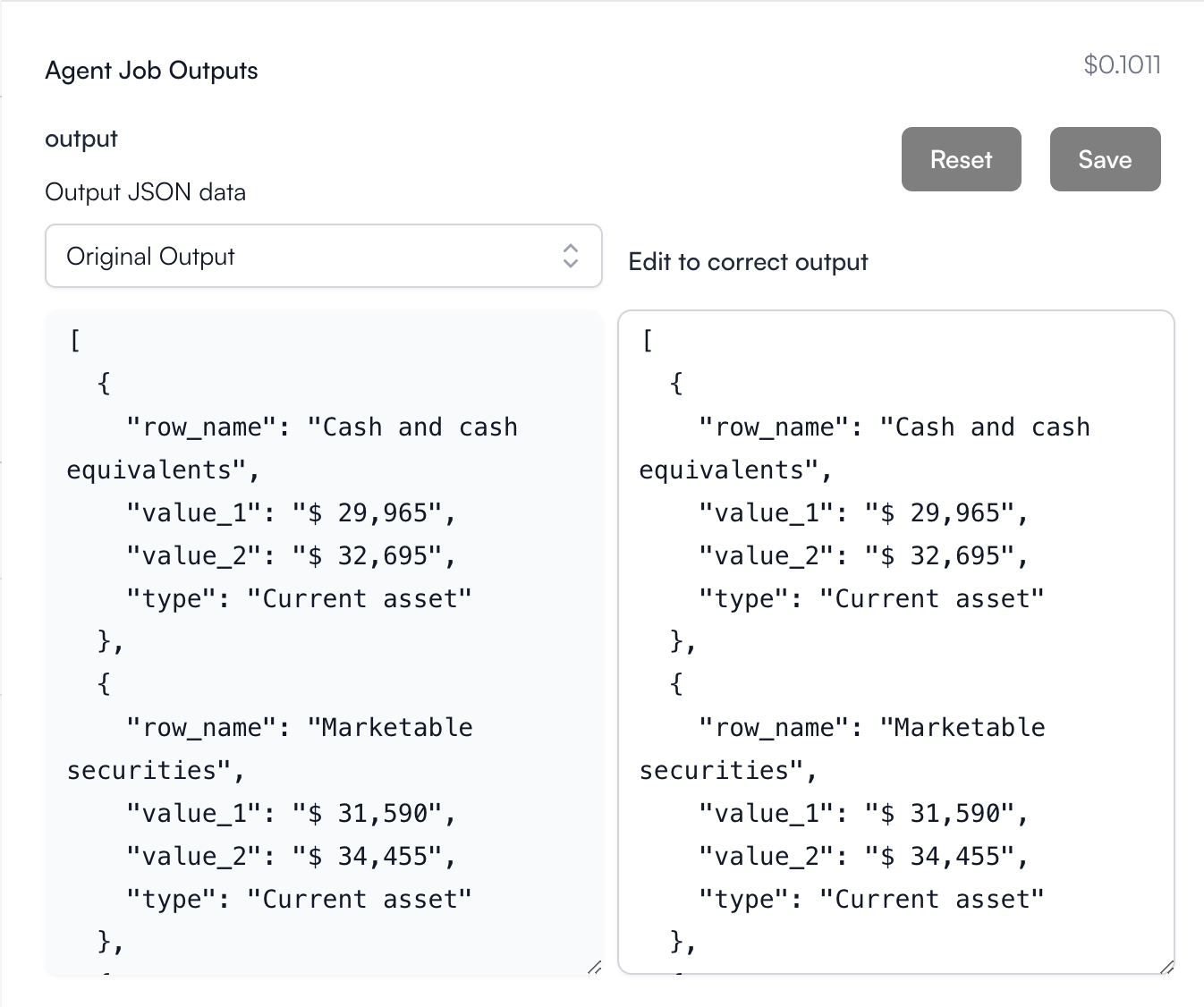
Create a new job and provide: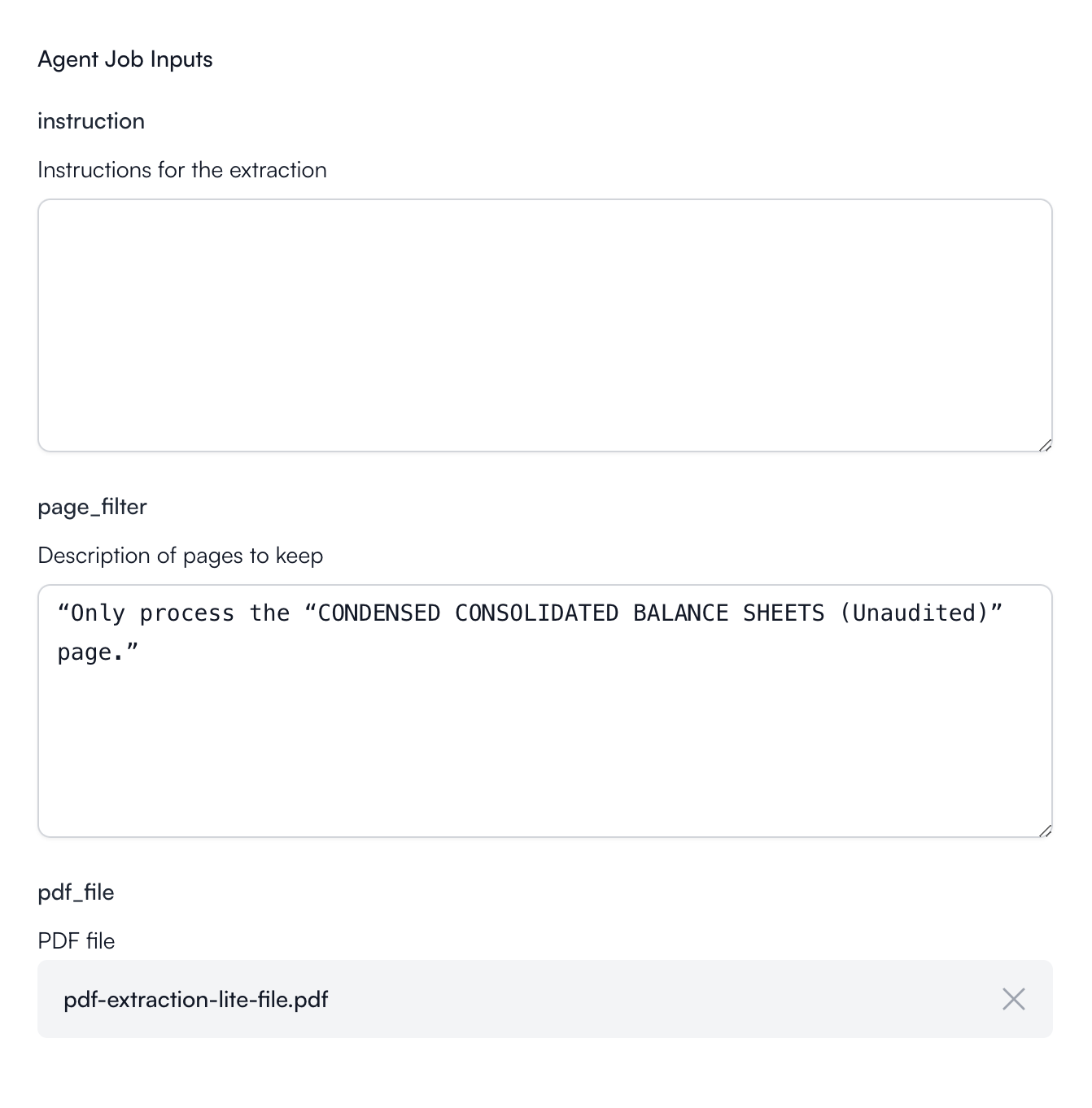
- instructions: “Extract all rows from the ASSETS table in the balance sheet”
- pdf_files: Upload or provide a URL to a PDF document